An effective approach to developing performant products in an agile environment
In modern days, performance testing and related practices are well established and carry out in various formats. But it was commonly seen that the testers and developers do not have established a way of conducting day to day performance related activities. Most of the time, no follow-ups happen when dealing with highly dynamic agile projects due to time constraints, overhead, delivery pressure, etc.
Through this model, we attempt to find a lasting solution to overcome such issues and make product performance assessments and optimizations much effective.
Main Phases of the cycle:
This performance engineering process contains several phases covering the full agile product development cycle. Each phase has own disciplines and practices that need to be implemented for the successful completion of the phase.
For example, in a Scrum based greenfield project, this process may contain three phases as shown below:
- Sprint 0 - Initial phase
- Sprint 1 to n - Development Phase
- Delivery Sprint - Deployment Phase
In the following sections, above phases are described with details and examples:
1. Sprint 0 – Initial Phase
Understanding the requirements and initial planning for performance engineering activities.
a. Understand the product architecture and get an idea about the system – In the first few days of the product development workshop, project members are discussing the high-level components and the architecture (DB, Web servers, Cloud, etc). Hence, we should be able to create some workflows and an architecture to portray the path.
Output – Initial architecture diagram which can depict the user flow
b. Gather Performance measurements and matrices from stakeholders using requirement gathering document – A set of standard questions to get the expected performance details from the customers. If they provide an SLA, then we can add those details as well to get things more clear.
Output – Documentation with information such as Peck hour usage, Concurrent usage.
c. Understanding the mission-critical requirements – If this application is a critical application, we need to make sure that all those modules are listed in a separate section
Output – A distinct listing of all the mission-critical user stories
d. Architecture assessment through “Architecture Tradeoff Analysis Method” or "Cost-benefit Analysis Method" - the Main idea of these methods are to calculate the ROI if we conduct performance assessments.
Output – Specify all the architectural components and identified costs and tradeoffs in related to performance assessments
e. Create a backlog for performance engineering requirements with specific filters – Filters can be varying upon the tool we are using to maintain bugs/issues.
Output – Distinct performance-engineering backlog items
2. Sprint 1 to n – Developing Phase
Validating the architecture on performance related nonfunctional attributes and carry out the continuous assessment and tuning activities.
a. Create a performance test strategy – Other than the main QA plan, we need to create a document that describes the scope of performance testing, infrastructure needs, tools, licensing cost, metrics, workload modelling, and results format
Output– Performance Strategy Documentation
b. Add performance engineering strategy to the main QA strategy document – Then we can get the big picture of the quality activities we have to do (Assuming other areas such as Security, etc., are also there).
Output– Comprehensive QA strategy document
c. Review the design and Architecture of the application – Conduct thorough review of the design, identify potential bottlenecks and create backlog items.
Output – backlog items for identified performance-related design drawbacks and are to be fixed in the Sprint n + 1.
d. Implement code-profiling tool in the project – Automate code reviews using a suitable tool (or combination of profilers) to test performance related code vulnerabilities
Output – Backlog items for identified implementation issues and preferably be fixed in the Sprint n + 1.
e. Build a mechanism to verify user story level performance by adding ‘Performance impacted’ area to each story
*Output –*User story level testing and create backlog items for identified bottlenecks
f. Conduct thorough front-end performance assessment – Before going for a complicated backend and CI implementation, need to evaluate the front end performance as most of the current web application bottlenecks are in the frontend.
Output – Well defined front-end performance test cases.
Backlog items for identified bottlenecks and should be fixed in the Sprint n+ 1

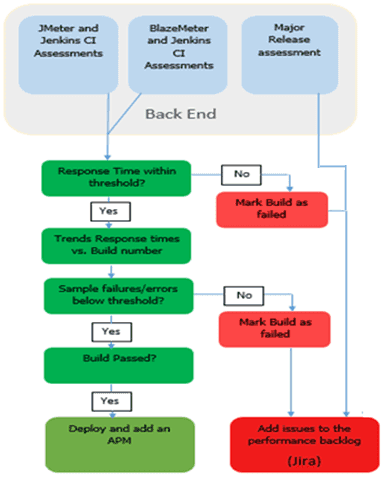
g. Implement Continuous performance assessment frameworks – Need to create a CI with daily performance assessment platform with threshold values.
*Output –*Well defined framework and Backlog items for identified bottlenecks and should be fixed in the Sprint n+1.
Sample CI:
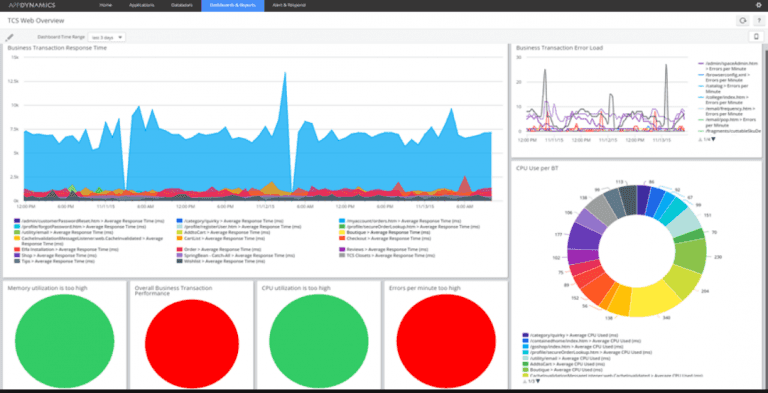
h. Create a well-defined dashboard to show all the daily performance figures – All the stakeholders can see the current figures of the application.
*Output –*Proper dashboard to make things visible to all the team members and stakeholders
i. Prepare the test environments according to the test plan (Cloud / on-premise) – Need to have a proper mechanism to prepare the test environment because all the figures are depending on this environment. Hence need to discuss this with the full team.
*Output –*Dedicated environment to conduct performance assessments
j. Conduct periodic fully-fledged performance assessments (Load Test) before any production releases
*Output –*Create a performance report. Create block log items and all the critical issues (Including issues which triggered in previous sprints) should be fixed before production release
Defect cycle:
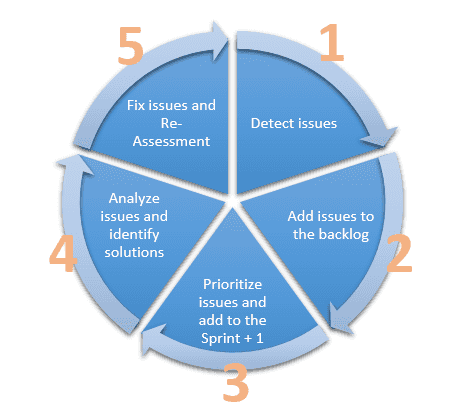
3. Delivery Sprint – Deployment Phase
Post-performance verification activities after deploying the product to the production environment:
a. Setup Performance Monitoring Systems – The production system/environment should be monitored using the Application Performance Management (APM) tool to detect performance issues in real time. In this case, we can use cloud solutions such as Azure application insights and AWS Cloud Watch or commercial applications such as New Relic, App dynamics, Monitis, etc.

Ensure notifications are raised for any possible issues
Output – Create backlog items for identified bottlenecks and should be fixed in the Sprint n + 1.
b. Conduct a proper capacity planning – After you deploy things to the production, you can get the real customer data to predict things for the future. In a growing business, capacity planning (forecasting) is a very vital part. In June 2018, if you have 500 users, we can predict the user volume in June 2020 by looking at the current data. We called this is the predictive approach.
Output – Document with all the planned activities for the future such as hardware upgrades, DB upgrades, etc.
After you're familiar with above phases and points, we can create following simple checklist to audit projects:




