
Runbyte: MCP, But Your Agent Writes Code
What happens when agents stop making tool calls and start writing code

If you've spent any time building with AI agents recently, you've probably noticed something frustrating. Getting agents to accomplish real workflows often feels like watching someone navigate a city by asking for directions one intersection at a time. "Turn left here?" Yes. "Now straight?" Yes. "Another left?" Yes. Each question burns tokens, adds latency, and clutters the context window with information the agent already processed.
Last December, during my vacation, I decided to tackle this problem head-on. The result is Runbyte, an open-source MCP server that lets AI agents write and execute TypeScript instead of making endless sequential tool calls.
This post covers the problem, how Runbyte approaches it, and where it's headed. For the full technical deep-dive into WebAssembly sandboxing, TypeScript generation, and architecture details, see the companion post on Medium.
The MCP Breakthrough (And Its Growing Pains)
Anthropic's Model Context Protocol changed everything about how AI agents interact with external tools. Before MCP, every integration required custom code. Every tool had its own authentication flow, its own schema format, its own quirks. Building an agent that could work with GitHub, Slack, and a database meant writing three separate integrations and hoping they played nicely together.
MCP unified all of that. Now we have a single standard for tool definitions, authentication, and communication. The ecosystem exploded almost overnight. GitHub, Slack, databases, file systems, CRMs, project management tools, there are MCP servers for nearly everything you'd want an agent to interact with.
But success created new challenges. When you connect an agent to multiple MCP servers with dozens of tools each, three problems emerge:
Token overhead from tool definitions. Every tool the agent might use needs to be described upfront in the context window. These definitions include parameter schemas, descriptions, examples, and constraints. Connect a few comprehensive MCP servers and you're burning through thousands of tokens before the conversation even starts. The agent needs to "know about" tools it might never use in a given session, and that knowledge isn't free.
Intermediate results polluting context. When an agent calls a tool, the result flows back through the context window. For multi-step workflows, this means the same information gets processed repeatedly. Query a database, process the results, update a record, send a notification, and every intermediate state accumulates in the conversation. By the end of a complex workflow, the context window is filled with data the agent processed five steps ago but doesn't need anymore.
Round-trip latency. Each tool call requires a round-trip to the model. The agent decides what to call, the system executes it, the result comes back, the agent decides what to do next. For workflows that might involve ten or twenty operations, this adds up fast. The agent sits idle, waiting, when it could be executing. Users watch loading spinners instead of seeing results.
Research That Pointed the Way
In September 2025, Cloudflare published their "Code Mode" approach, showing how agents could write TypeScript to orchestrate tools on Cloudflare Workers. Instead of calling individual tools through a structured interface, agents wrote actual code that expressed their complete intent. The pattern was clear: giving agents the ability to express intent as executable code fundamentally changes the economics of tool orchestration.
A few weeks later, Anthropic published research on"Code Execution with MCP"that demonstrated something remarkable. By letting agents write code that navigates a filesystem to discover tools progressively, rather than loading all tool definitions upfront, they achieved a 98.7% reduction in tokens specifically for this progressive disclosure pattern. The key insight: instead of dumping every tool schema into the initial context, agents explore a virtual directory structure, reading only what they need when they need it.
An agent working with a filesystem MCP server doesn't need to load definitions for 50 tools upfront. It can start with a simple directory listing, then read documentation for only the specific operations it actually needs.
I wanted to bring these ideas together into something practical.
What Runbyte Actually Does
Runbyte sits between your AI agent and the MCP servers you already have. It transforms the traditional "call tools one at a time" model into "write code that accomplishes your goal."
Here's the core idea: Runbyte generates TypeScript APIs from your existing MCP tools and exposes them through a virtual filesystem. Agents discover capabilities by exploring directories and reading files, then write TypeScript that uses those APIs. The code executes in a WebAssembly sandbox, keeping everything secure and isolated.
The entire interface is just three tools:
- list_directory: Explore available servers and workspace files
- read_file: Read TypeScript definitions or workspace data
- execute_code: Run TypeScript that orchestrates multiple operations
That's it. Three tools instead of dozens.
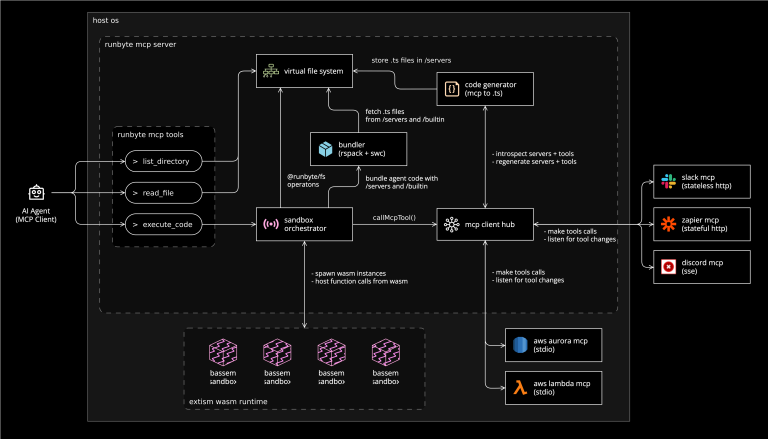
The architecture diagram shows the flow. Your agent connects to Runbyte, which maintains connections to your various MCP servers. Runbyte automatically generates TypeScript type definitions from each server's tool schemas. When the agent needs to accomplish something, it explores the /servers/ directory to see what's available, reads the generated TypeScript definitions to understand the APIs, and writes code that executes against those APIs.
The WebAssembly sandbox is critical here. Code executes in an isolated environment with controlled access to external resources. The agent can't accidentally (or maliciously) access the filesystem, network, or other resources outside what's explicitly provided through the MCP servers. This sandboxing makes it safe to execute agent-generated code without worrying about unintended side effects.
A Practical Example
Let's make this concrete. Say you want an agent to find all orders over $1,000 from today, log them in Airtable, and alert the sales team on Slack.
Traditional MCP Approach
With conventional tool calling, the agent needs multiple round-trips:
Agent: shopify/list_orders { created_after: "2025-02-04" }
→ Returns 50 orders (~8,000 tokens flowing into context)
Agent: (filters to 8 high-value orders, then calls Airtable for each)
Agent: airtable/create_record { table: "High Value Orders", fields: { ... } }
→ Returns success
Agent: airtable/create_record { table: "High Value Orders", fields: { ... } }
→ Returns success
... (6 more Airtable calls)
Agent: slack/post_message { channel: "#sales", text: "8 high-value orders today..." }
→ Returns success
That's at least 11 tool calls. Each one requires the agent to formulate the call, generate the tool invocation, wait for execution, receive results back into context, and decide what to do next.
Every intermediate result sits in the context window as the agent processes subsequent calls. The full order list flows in, the agent filters it, then re-serializes each high-value order into Airtable calls. The agent is essentially thinking out loud at every step, and you're paying for all that thinking.
Runbyte Approach
With Runbyte, the agent explores the available tools first:
Agent: list_directory("/servers")
→ shopify/, airtable/, slack/
Agent: list_directory("/servers/shopify")
→ listOrders.ts, getOrder.ts, createOrder.ts, ...
Agent: read_file("/servers/shopify/listOrders.ts")
→ TypeScript with types and API documentation
Agent: read_file("/servers/airtable/createRecord.ts")
→ TypeScript with types and API documentation
Agent: read_file("/servers/slack/postMessage.ts")
→ TypeScript with types and API documentation
Then it writes a single program:
import * as shopify from './servers/shopify';
import * as airtable from './servers/airtable';
import * as slack from './servers/slack';
// Fetch today's orders
const orders = await shopify.listOrders({
created_after: new Date().toISOString().split('T')[0]
});
// Filter high-value orders
const highValue = orders.filter(o => o.total_price > 100000); // cents
// Log each to Airtable
for (const order of highValue) {
await airtable.createRecord({
table: "High Value Orders",
fields: {
OrderNumber: order.order_number,
Customer: order.customer_email,
Amount: order.total_price / 100,
Date: order.created_at
}
});
}
// Notify sales team
const total = highValue.reduce((sum, o) => sum + o.total_price, 0) / 100;
await slack.postMessage({
channel: "#sales",
text: `${highValue.length} high-value orders today! Total: $${total.toLocaleString()}`
});
return { processed: highValue.length, total };
One execute_code call. The agent expressed its complete intent as code, and Runbyte handled the orchestration. The intermediate results (all 50 orders) never needed to flow back through the model's context window. The filtering happened inside the sandbox, invisible to the model.
The difference is significant. The agent thought once, expressed a complete solution, and let the runtime handle execution. No back-and-forth, no accumulated context, no waiting for each step to complete before planning the next.
The Virtual Filesystem
The /servers/ directory contains a subdirectory for each connected MCP server. Inside each server directory, you'll find individual TypeScript files for each tool:
/servers/
├── shopify/
│ ├── listOrders.ts
│ ├── getOrder.ts
│ ├── createOrder.ts
│ └── index.ts
├── airtable/
│ ├── createRecord.ts
│ ├── listRecords.ts
│ └── index.ts
└── slack/
├── postMessage.ts
├── listChannels.ts
└── index.ts
Each tool gets its own file with full type definitions and API documentation. The index.ts re-exports everything, enabling namespace imports like import * as shopify from './servers/shopify'. This one-file-per-tool approach enables progressive loading: an agent can read just listOrders.ts without loading definitions for other Shopify tools it doesn't need.
The type definitions are generated automatically from MCP tool schemas. When you add a new MCP server to your Runbyte configuration, it introspects the server's capabilities and generates corresponding TypeScript. Agents get full type information, which helps them write correct code on the first try.
There's also a /workspace/ directory where agents can persist data between executions. This becomes important for more complex workflows where you might want to cache intermediate results, maintain state across multiple code executions, or build up outputs incrementally. Files in the workspace persist for the duration of the session, allowing for more sophisticated multi-step interactions.
What's Next: Workflows as Functions
Building Runbyte revealed an interesting possibility. If agents can write TypeScript that orchestrates tools, they can also write TypeScript functions that represent reusable workflows.
We're working on features that let agents author workflows as parameterized, schedulable TypeScript functions:
// Agent-authored workflow
export async function dailySalesReport(
threshold: number = 1000,
slackChannel: string = "#sales"
) {
const orders = await database.query(
`SELECT * FROM orders WHERE amount > ${threshold} AND date = CURRENT_DATE`
);
const summary = {
count: orders.length,
total: orders.reduce((sum, o) => sum + o.amount, 0),
topCustomers: orders
.sort((a, b) => b.amount - a.amount)
.slice(0, 5)
.map(o => o.customer_name)
};
await slack.sendMessage(slackChannel, formatSalesReport(summary));
return summary;
}
// Schedulable: Run daily at 6 PM
export const schedule = "0 18 * * *";
Imagine telling an agent "create a workflow that monitors our support queue and escalates tickets that have been open for more than 4 hours." The agent writes the function, tests it against sample data, and schedules it for continuous operation. The workflow becomes a first-class artifact that can be versioned, reviewed, and composed with other workflows.
This moves us toward reliable automation that's still flexible. Agents handle the creative work of translating intent into code. The runtime handles execution guarantees, scheduling, and error recovery. Humans retain oversight through code review and approval workflows. It's the best of both worlds: the adaptability of AI with the reliability of traditional software.
The Bigger Picture for Organizations
We're seeing a shift in how organizations can think about automation. Traditional approaches require either rigid pre-built workflows that break when requirements change, or expensive custom development for every new process. Agent-driven automation has been promising but unpredictable. Agents are great at handling varied situations but can be unreliable when you need consistent execution.
Code execution bridges these worlds. Agents get the expressiveness they need to handle varied situations. Organizations get the reliability of executable, reviewable code. The WebAssembly sandbox provides security boundaries that make it safe to run agent-generated code. TypeScript catches type errors during bundling, helping agents write correct code on the first try.
For engineering teams, this means less time building bespoke integrations and more time defining the APIs and guardrails that agents operate within. For operations teams, it means automation that can adapt to new situations without requiring engineering intervention for every edge case.
Try It Out
Runbyte is open source and available now. For a deeper technical walkthrough of the architecture, sandbox implementation, and the design decisions behind them, check out the companion post on Medium.
This started as a vacation project last December, a chance to explore ideas from Anthropic and Cloudflare and see what a practical implementation might look like. The Workflows as Functions vision came from Hasith Yaggahavita, and it's turned into something I think could genuinely change how we build with AI agents.
We're just getting started. If you're interested in agent orchestration, workflow automation, or just want to reduce your token bills while getting more reliable results, give Runbyte a look. I'd love to hear what you build with it.