
Building a Robust Database AI Agent with GraphQL and MCP
A practical look at building a safe AI database agent that uses GraphQL and progressive schema discovery to let LLMs query structured data without hallucinating or writing raw SQL.
.png)
The Challenge:
Connecting large language models (LLMs) to structured data is powerful but risky if done carelessly. Letting a model generate raw SQL can introduce, security concerns, and hard-to-debug behaviour.
A more robust approach is to constrain the model with a typed, discoverable interface. That’s exactly what this architecture achieves using GraphQL and a lightweight tool protocol.
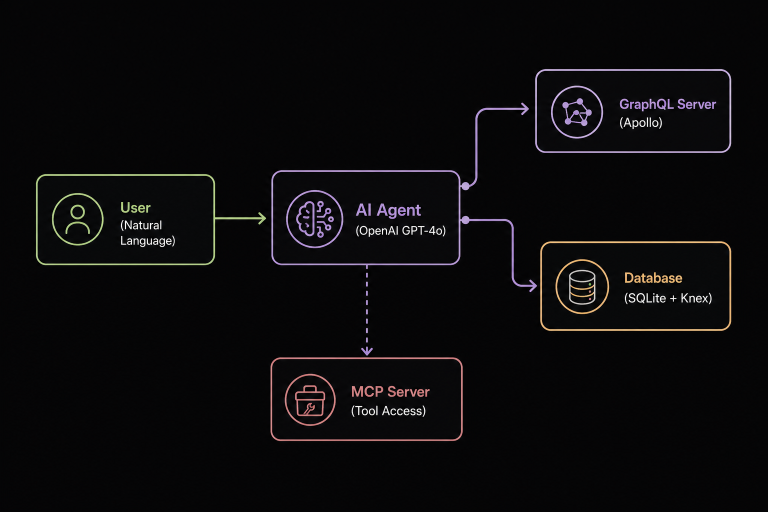
Architecture Overview
At a high level, this system combines a TypeScript (Node.js) backend, an in-memory SQLite database (via Knex.js), an Apollo GraphQL API, and an LLM-powered agent that interacts with the data through a controlled tool layer. An MCP-compatible server exposes these tools for external use, making the system modular and extensible.
The runtime flow is simple but effective:
.png)
- A user sends a natural language query via CLI
- The agent interprets the request and progressively discovers available data structures
- It inspects GraphQL types dynamically (instead of guessing fields)
- It constructs a minimal graph query and executes it
- The GraphQL layer resolves data using a resolver and returns structured results
This “progressive discovery” loop is the key to prevents hallucination by ensuring the model only uses verified schema information.
Simple Example: End-to-End Agent Flow
To understand how this works in practice, let’s walk through a real interaction.
User Prompt
“Who are the users and what are their roles?”
Step 1: Discover Available Queries
The agent begins by calling:
list_queries()
Response:
["users", "posts", "comments", "categories", "user", "post"]
This tells the agent what entry points exist—no guessing required.
Step 2: Inspect Schema
Next, the agent inspects the user's query:
inspect_query("users")
Response:
{
"fields": ["id", "name", "email", "role", "createdAt", "posts"]
}
Now the agent knows exactly which fields are valid.
Step 3: Construct a Safe Query
Using only discovered fields, the agent builds:
query {
users {
id
name
role
}
}
Step 4: Execute Query
execute_graphql(query)
Response:
[
{ "id": 1, "name": "Alice", "role": "ADMIN"},
{"id": 2, "name": "Bob", "role": "USER" }
]
Final Output
Alice – ADMIN
Bob – USER
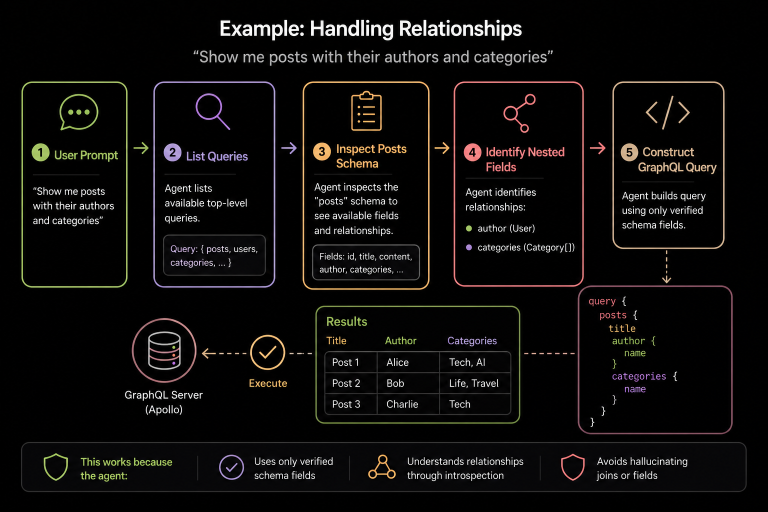
User Prompt
“Show me posts with their authors and categories”
The agent repeats the same discovery process:
- Lists queries
- Inspects posts schema
- Identifies nested fields (author, categories)
Then constructs:
query {
posts {
title
author {
name
}
categories {
name
}
}
}
This works because the agent:
- Progressively discover the data schema
- Uses only verified schema fields
- Understands relationships through introspection
- Avoids hallucinating joins or fields
Reference Implementation
Database (src/db.ts)
Defines schema (users, posts, comments, etc.) and seeds data using SQLite in-memory. This ensures reproducibility and quick startup.
GraphQL API (src/graphql.ts)
Uses Apollo Server with introspection enabled. Resolvers are intentionally narrow, promoting pagination and controlled data access.
Agent (src/agent.ts)
Orchestrates interactions with the LLM. It exposes three tools:
- list_queries() – returns available entry points
- inspect_query(name) – returns type fields and structure
- execute_graphql(query) – executes validated queries
MCP Server (src/mcp.ts)
Makes these tools accessible over HTTP for external agents or services.
Engineering Considerations
Error Handling
If a query fails (e.g., schema mismatch), the agent re-inspects and retries intelligently.
Performance
Add caching for schema introspection and enforce query complexity limits.
Testing
Unit tests validate each tool, while integration tests verify end-to-end behaviour with the seeded database.
Scalability
Swap SQLite for Postgres, add RBAC in resolvers, and deploy MCP endpoints for multi-agent use.
Conclusion
This architecture demonstrates a practical pattern for safely connecting LLMs to structured data. By combining GraphQL’s typed interface, tool-based interaction, and a discovery driven agent loop, it creates a system that is both powerful and predictable.
The pattern scales well: you can introduce persistent databases, caching layers, and authorization mechanisms without changing the core design. If you’re building AI systems that interact with real data, this approach offers a strong foundation balancing flexibility with control.